react-markdown をやめて remark から自力でレンダリングするようにした話
Intro
このブログサイトの記事ページではこれまで react-markdown というライブラリでマークダウンを HTML に変換して表示していました。この度、react-markdown を剥がして remark を直接使って記事をレンダリングするように変更しました。
前回の記事で Playwright で VRT を導入した記事を書きました。VRT でデグレチェックをしたかったのはこの変更を加えたかったからです。Playwright のおかげで表示崩れすることなく移行することができました。
react-markdown について
react-markdown は unified/remark/rehype を使ってマークダウンを解析し、適切な要素をレンダリングする React コンポーネントを提供します。
remark はマークダウンから mdast(Markdown Abstract Syntax Tree)への変換、rehype は hast(Hypertext Abstract Syntax Tree) から HTML への変換(その逆も含む)を行うモジュールです。unified はそれらを統一的に扱うためのインターフェイスを提供するやつらしい(よくわからない)。mdast と hast を繋ぐやつもあります。
unified/remark/rehype でマークダウンを処理する流れとかプラグインの仕組みの解説は、次の記事が非常に参考になるので貼っておきます。
どんな使い方か
<ReactMarkdown>{children}</ReactMarkdown> とすることで、children に渡したマークダウン文字列を HTML に変換してくれます。使いたい remark プラグインや rehype プラグインがある場合は、それぞれ props 経由で渡しておくと内部の変換処理で使ってくれるようになります。多くの人がここで GitHub のマークダウン方言を使うために remarkGfm を指定することになるでしょう。
<ReactMarkdown
remarkPlugins={[remarkFrontmatter, remarkGfm]}
rehypePlugins={[rehypeSlug, rehypeHighlight]}
components={{
a: MDLink,
code: Code,
p: Paragraph,
img: Img,
}}
>
{children}
</ReactMarkdown>特定のHTML要素に対して独自のコンポーネントを適用したい場合は components に要素ごとに指定します。HTML要素ごとというのがポイントです。
レンダリング結果にこだわりがなければ、そのまま使うことが気にならないかも知れません。しかし、ちょっと方言を増やして独自コンポーネントを差し込みたいとなるとつらくなってきます。
なぜつらいのか
HTML の単位とマークダウンの「意味」の単位が一致しない場合が多いからです。例えばコードブロックを意味する次のマークダウンは
```ts
const foo = document.createElement("div");
```rehypeHighlight によって次の HTML に変換されます。
<pre><code class="hljs language-ts"><span class="hljs-keyword">const</span> foo = <span class="hljs-variable language_">document</span>.<span class="hljs-title function_">createElement</span>(<span class="hljs-string">"div"</span>);
</code></pre><pre> も <code> も <span> も出てきました。1つのコードブロックを表現するのに HTML 要素を 3 つ使用しています。
一方で react-markdown では HTML 要素ごとにコンポーネントを適用します。マークダウンではコードブロックだけでなくインラインコードも <code> 要素に変換されます。インラインコードに対して独自のコンポーネントを適用しようと思ったらコードブロックにも当たっていたなんてことが起こるのです。
このブログでは、段落一つに URL だけを含む場合ブロックレベルリンクとみなしてリンク先のOGPを表示するリンクカードを描画するようにしています。その URL が Twitter のツイートページや YouTube の動画ページの場合はそれぞれの埋め込み iframe への変換もしています。次はそのリンクの例です。
https://zenn.dev/chot/articles/introduction-of-next-third-parties
https://twitter.com/jack/status/20
https://www.youtube.com/watch?v=cyFB7sB6CYsこれを実装するために、<p> に対応するコンポーネントを用意して、その node.children を掘って分岐を書いていました。
const Paragraph: Components["p"] = ({ node, ...props }) => {
const child = node?.children[0];
if (
node?.children.length === 1 &&
child?.type === "element" &&
child.tagName === "a" &&
typeof child.properties?.href === "string" &&
child.children[0].type === "text" &&
child.properties.href === child.children[0].value
) {
if (
// Twitter の Tweet URL
/https?:\/\/(www\.)?twitter.com\/\w{1,15}\/status\/.*/.test(child.properties.href)
) {
return (
<div className={classes.embeded}>
<ArticleTweetCard url={child.properties.href} />
</div>
);
}
const videoId = extractYouTubeVideoId(child.properties.href);
if (videoId) {
return (
<div className={classes.embeded}>
<YouTubeEmbed videoId={videoId} />
</div>
);
}
return (
<div className={classes.embeded}>
<RichLinkCard href={child.properties.href} isExternal />
</div>
);
}
return <p {...props} />;
};node の children が1つだけでそれが a 要素で href と value が同じだったら、、、href が Twitter だったら、、、YouTube だったら、、、なんて分岐を1つのコンポーネントで頑張っていたんですね。そうではなく、mdast の時点で「これはブロックリンク、これは Twitter 埋め込み、これは YouTube 埋め込み」と意味を区別しておいて、それぞれに1個ずつコンポーネントを用意してやりたいんです。
非同期プラグインに未対応
remark や rehype は処理途中の AST を書き換える処理をプラグインとして挟むことができます。GitHub 風のマークダウン方言を使えるようになる remarkGfm もそのひとつ。その書き換え処理は非同期もサポートされています。
react-markdown は remark や rehype のプラグインを渡すことができますが、非同期で実行されるプラグインはエラーになり使えません。次のような issue も上がっていますが進展はありません。
そもそも従来の React コンポーネントが非同期処理に対応していないので進展もなにもないと思いますけどね…。react-markdown は与えられた文字列をコンポーネントのレンダリングフェーズで変換しているので、非同期処理になってしまうと React コンポーネントになり得ません。React Server Components になれば別ですが、それをやってしまうと(少なくとも今は) Next.js 専用になってしまうので、それはそれで困る人が多いでしょう。
なぜ僕が非同期プラグインが使えなくて困ったかと言うと、Syntax Highlighter を highlight.js から shiki に乗り換えたいなと思っていたからです。remark-shiki-twoslash という shiki 側提供の公式プラグインがあるのですが、これが非同期プラグインとして実装されていました(そもそも shiki が非同期 API しか提起していませんから当然ですね)。なので、shiki でコードブロックの色付けをするには脱 react-markdown が必須だったのです。
余談なんですけど、React.use の安定版が提供されたらこういうのもどんどん使えるようになるのかな。Client Component でもレンダリングフェーズに非同期処理がしたいんじゃぁ。
remark だけ使う
そして考えた結果、rehype まで含んで hast にしてしまうのがダメなんだと気づきます。マークダウンの「意味」の単位に対してコンポーネントを適用していきたいのに、mdast をさらに砕いた hast を処理するからいけないのだと。「マークダウンの意味ごとに分類されたデータ構造」である mdast から直接 React コンポーネントに変換すれば、理想の設計が実現できます。
また、このブログは Next.js App Router なので React Server Components にもできます。つまり非同期処理も思うがままに扱えます。shiki を使えちゃう。
ということでやっていきましょう。
プロセッサーを用意する
次のように remark とプラグインを組み合わせてプロセッサーを作ります。
import { RootContent, RootContentMap, PhrasingContent } from "mdast";
import { remark } from "remark";
import remarkFrontmatter from "remark-frontmatter";
import remarkGfm from "remark-gfm";
import { remarkLinkBlock } from "@/lib/remark-link-block";
import { remarkTwitterEmbed } from "@/lib/remark-twitter-embed";
import { remarkYouTubeEmbed } from "@/lib/remark-youtube-embed";
const parseMarkdown = remark()
.use(remarkFrontmatter)
.use(remarkTwitterEmbed)
.use(remarkYouTubeEmbed)
.use(remarkLinkBlock)
.use(remarkGfm);このブログでは記事のメタ情報を frontmatter に書いているので remarkFrontmatter を入れます。これは npm で配布されているライブラリです。
remarkTwitterEmbed, remarkYouTubeEmbed, remarkLinkBlock は独自プラグインです。内部実装については後述します。remarkLinkBlock を remarkTwitterEmbed, remarkYouTubeEmbed よりも後に登録していることは重要です。
そしてやはり GitHub 風のマークダウンを使いたいので remarkGfm は必須です。これも npm ライブラリです。
注目すべきポイントは rehype に関するライブラリを導入していないことですね。hast や HTML に変換しないことにしたので、rehype は不要です。
このプロセッサーに mdast を生成してもらうには次のようにします。
const parsed = parseMarkdown.parse(markdownText);
const mdastRoot = await parseMarkdown.run(parsed);これでマークダウン文字列から mdast が得られるようになりました。
全ての node を自力で描画する
これまでは react-markdown がマークダウンを HTML まで変換してくれていました。しかし今は mdast までしか変換していません。mdast に含まれる node すべてに対応した JSX(React コンポーネント) への変換を用意してやる必要があります。
mdast(抽象構文木)はその名の通りツリー構造なので、再帰的なコンポーネントを用意します。
const NodesRenderer: FC<{ nodes: RootContent[] }> = ({ nodes }) => {
return nodes.map((node, index) => {
switch (node.type) {
case "text": {
return <TextNode key={index} node={node} />;
}
case "paragraph": {
return <ParagraphNode key={index} node={node} />;
}
// その他 node.type に対応するコンポーネントを返す
}
});
};
const TextNode: FC<{ node: RootContentMap["text"] }> = ({ node }) => {
return node.value;
};
const ParagraphNode: FC<{ node: RootContentMap["paragraph"] }> = ({ node }) => {
return (
<p>
<NodesRenderer nodes={node.children} />
</p>
);
};NodesRenderer が ParagraphNode をレンダリングしますが、ParagraphNode は NodesRenderer をレンダリングします。いずれ children を持たない leaf node(例えば TextNode) に到達するので、無限ループにはなりません。
このように node.type に応じたコンポーネントを1個ずつ用意していきます。基本的には <p> とか <h2> とかを返すだけですけどね。
remark plugin を作る
URL だけを含む paragraph node をブロックレベルリンク(リンクカード)に変換する独自プラグインを作成します。
ブロックレベルリンクに対応する mdast の node の型を用意したいので、mdast の型定義を拡張します。BlockLink という型を定義し、RootContentMap に登録します。TypeScript の interface declaration merging を活用しています。
declare module "mdast" {
export interface BlockLink extends Resource {
type: "block-link";
}
interface RootContentMap {
"block-link": BlockLink;
}
}これで mdast 名前空間に独自ブロックを認識してもらえるようになったので、続いて変換処理を書きます。
import { Root } from "mdast";
import { Plugin } from "unified";
import { visit } from "unist-util-visit";
export const remarkBlockLink: Plugin<[], Root> = function () {
return (tree: Root) => {
visit(tree, "paragraph", (node, index, parent) => {
const maybeLink = node.children[0];
if (node.children.length !== 1) return;
if (maybeLink.type !== "link") return;
if (maybeLink.children.length !== 1) return;
const isPlainLink =
maybeLink.children[0].type === "text" &&
maybeLink.url === maybeLink.children[0].value;
if (!isPlainLink) return;
if (!parent || index === undefined) return;
parent.children[index] = {
type: "block-link",
url: maybeLink.url,
};
});
};
};unist-util-visit というライブラリが特定の node に対して処理を実行するユーティリティを提供しているのでこれを使います(Visitor パターンというのがあるらしい)。visit の第3引数の関数で受け取れる引数は、対象の node とその親 node、そして対象 node が親 node の何番目に位置するかの index です。これを paragraph node を対象に実行します。ブロックレベルリンクとみなしたい条件をつらつら書いていき、条件が一致したら対象の paragraph node を置き換えるように親 node の children を書き換えます。これを上の方で定義したプロセッサーに渡しておけば、.run() 実行時に変換処理が走るようになります。
同様に remarkTwitterEmbed と remarkYouTubeEmbed も用意します。Embed と名付けていますが、node に識別子と URL を付けておくだけで、実際に Embed するのは React コンポーネントです。remarkTwitterEmbed と remarkYouTubeEmbed も paragraph に link がただひとつ含まれるときに変換します。remarkBlockLink が先に処理を実行してしまうと link ではなく block-link になってしまうので、プラグインの登録順に注意が必要です(上の方参照)。
これで mdast に独自 node が挿入されるようになるので、React コンポーネントの対応付けもしておきましょう。React コンポーネントの中身が何をしているかはソースコードを御覧ください。
const NodesRenderer: FC<{ nodes: RootContent[] }> = ({ nodes }) => {
return nodes.map((node, index) => {
switch (node.type) {
// プリミティブな node.type いろいろ省略
case "block-link": {
return <BlockLinkNode key={index} node={node} />;
}
case "twitter-embed": {
return <TwitterEmbedNode key={index} node={node} />;
}
case "youtube-embed": {
return <YouTubeEmbedNode key={index} node={node} />;
}
}
});
};これで mdast を直接使用して React コンポーネントに変換する処理の完成です。自前で remark プラグインを作り独自 node を追加することで、React コンポーネントでごちゃごちゃした分岐を書く必要がなくなりました。
shiki を導入する
shiki は Syntax Highlighter ライブラリで、Visual Studio Code と同じ仕組みで処理を行っているので、Visual Studio Code と同じシンタックスハイライトを実現できます。
shiki の導入については remark のプラグインなどは関係なく、単にコードブロック node をどう装飾するかの問題です。remark でコードブロック node に lang と value が渡されているので、これを shiki で html 文字列に変換して dangerouslySetInnerHTML にぶちこむだけです。
const CodeNode: FC<{ node: RootContentMap["code"] }> = async ({ node }) => {
const lang = node.lang ?? "";
const highlighted = await highlightWithShiki(node.value, lang);
return <div dangerouslySetInnerHTML={{ __html: highlighted }} />;
};shiki の html 変換は非同期処理になりますが、React Server Components なのでこれで動きます。CSS は別途調整が必要ですが、.shiki クラスに対してちょろっと書いただけなので割愛します。
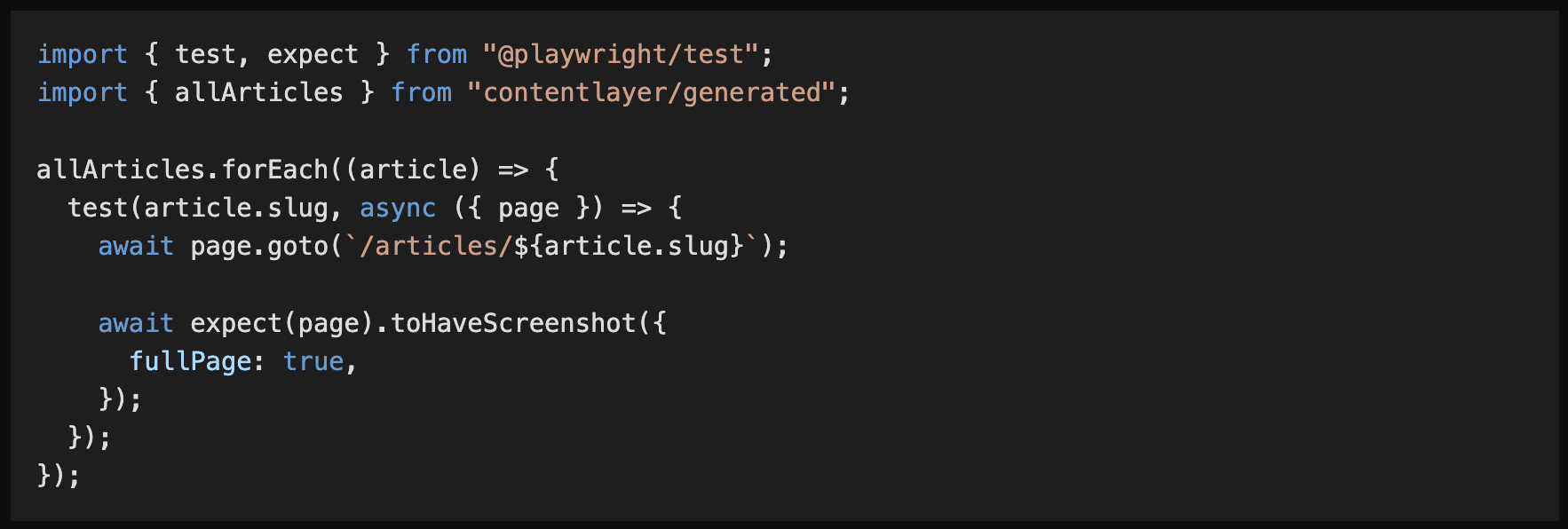
highlight.js と shiki の違いを見てみましょう。
highlight.js
shiki
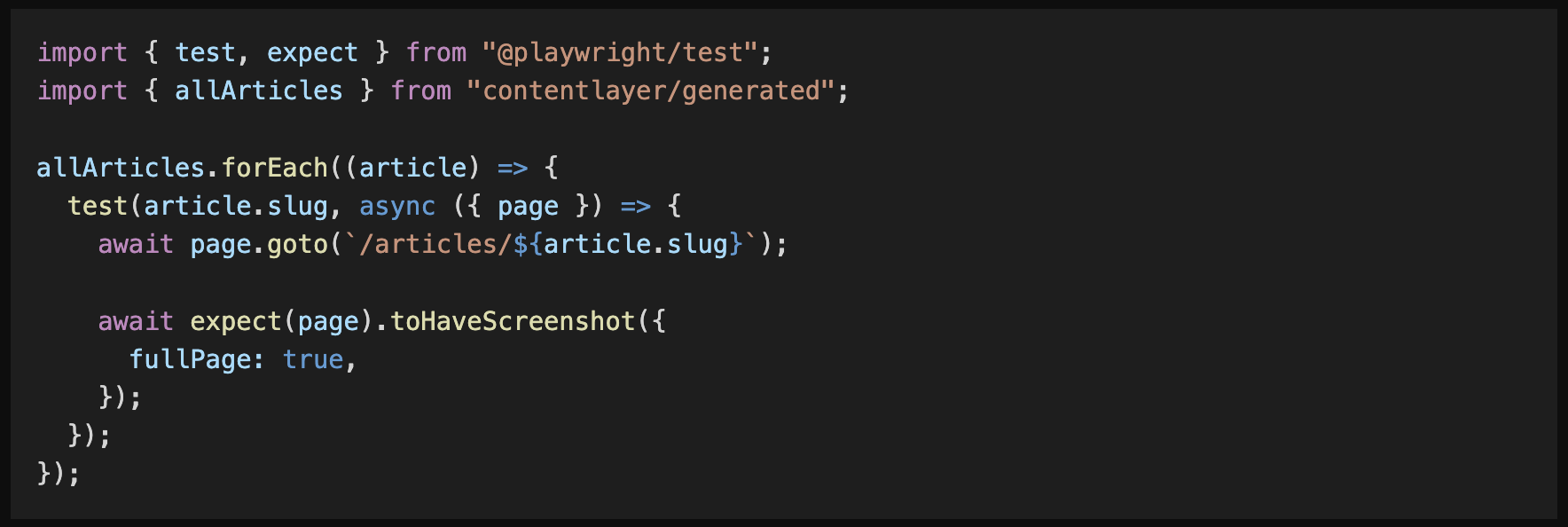
より Visual Studio Code に近いカラフルなシンタックスハイライトを実現できています。highlight.js の色数は物足りなかったんですよね。またひとつブログを書くモチベーションがアップしますね、多分。
まとめ
react-markdown で行っていた記事ページの描画を remark を直接使って自力でレンダリングするようにした話を書きました。ついでに Syntax Highlighter を highlight.js から shiki に変更できました。
react-markdown は内部で remark と rehype を使ってマークダウンを HTML に変換しますが、少し自分の設計思想とはミスマッチだったり非同期プラグインが使えない問題がありました。remark を直接使って mdast を得ることで、マークダウンの「意味」に対して自由に React コンポーネントを適用できるようになりました。
Syntax Highlighter は入れ替えたい気持ちが強かったので、ついでに実現できて良かったです。shiki はいいぞ。みなさんも使ってみてください。
それでは良い remark ライフを!
